
.
Even with all the buzz and hype over the last few years circulating network automation, only a few companies seem to realize the true benefits of proper end-to-end network automation from both a business and technology standpoint. Looking closer, there is a crucial topic not addressed in the many discussions on network automation. It gets kicked to the side by the introduction of glossy technologies and vendor solutions.
When you remove all the fancy ideas pushed by networking vendors and NFV/SDN evangelists and focus on the core automation challenge, what we really are talking about is operational efficiency and information management. More specifically, how can we optimize and automate the operational change processes and its required information flows.
Interestingly enough, this has nothing to do with the networking technologies you choose to implement, but everything with how you manage your information and change processes during your engineering activities. Getting this right allows you to automate the hell out of any network, even your legacy ones.
Networking Industry Challenges
It’s a given that every network is a unique snowflake. Never will you see two identical networks. More than often, they entail a variety of products and technologies from different vendors creating one unique network after another. Typically in Service Provider environments, vendor A is deployed for Access layer, vendor B for Core and vendor C for the WAN edge. Products can address the same functionalities but each vendor implements them in a different way (example: MLAG from Arista, VPC, and VSS from Cisco).
The products offered by networking vendors merely act as building blocks for smart engineers to design solutions that work. An IP VPN solution from provider A can offer the same service as Provider B, but as there are so many ways to design and implement things, today’s manual-driven approach simply creates a huge variety of designs and configurations. The freedom of network architecture simply allows for millions of unique networks.
So every network is uniquely designed to fit the company’s requirements with their own footprint and legacy networks to support. On top of that, services are individually tailored due to sales teams driving product managers to customize offerings to win the sale. So even when services may be designed as ‘standard’, it’s still an ART for network engineers to implement them.
But while network engineers are brilliant ‘artists’ at designing solutions that work, there is a big difference whether these solutions are the best in terms of deployability, manageability, stability and overall efficiency.
Today’s Focus
Unfortunately, today’s culture is still looking at network devices individually. In itself, this is understandable as, in the end, each device needs to be configured for a service to work, but a box-by-box focus to solve the overall challenge severely limits network scalability and efficiency. It introduces cumbersome operations leading to human error.
CLI (command-line interface) provisioning is still the most common method for configuration changes but it has a number of drawbacks. It offers the wrong level of abstraction and it’s targeting the human operator. There is no validation whether engineers follow the correct procedures before making config changes. The CLI generates error messages but it’s only on a ‘trial and error’ basis in your production network to know whether they work. No measures are taken to prepare config changes before touching the CLI and guarantee error-free changes.
And as CLI languages are not standardized across multi-vendors, CLI provisioning in a multi-vendor environment requires even more challenges. Sometimes tailored scripts are used, but source- and version control, bugs and changes become the author’s responsibility. Scripts are never usually an official tool for the company and more than often management is carried out in the author’s spare time. Automating little bits of your daily job with individual scripts is therefore not the way forward. One should look to automate the network as a whole.
The networking industry reacted and introduced standards-based protocols to communicate across multiple vendors. NETCONF was introduced as an XML structured format across multiple vendors, enabling the first step for devices and vendors to standardize on. This was certainly a welcomed improvement enabling a more standard way to communicate using a structured format.
However, protocols like NETCONF have also proven to be vendor specific for each implementation. NETCONF has many inconsistencies across vendor operating systems. Many vendors use their own proprietary format making it hard to write NETCONF applications across multiple vendor operating systems. There is the inconsistency with TCP ports and subsystems names, some produce XML output while others show command output, etc.
NETCONF is meant to make automation easy but these irregularities can make automation even more difficult. And again, it only focuses at the device level. It lacks the awareness of topologies and services and does not take into account the process and information flow.
Among all these varieties, deployment options and complexities, engineers often lose faith in network automation but complexity does not mean you can’t automate. More and more organizations have been able to automate their multi-vendor, multi-domain and even legacy networks. So why not learn how they did it!
The way forward – start looking in the right direction
What you want to achieve is a tight coupling of your design rules and your network and move away from trial and error in production. This requires us to look at the process and information flow before we automate anything at a device level.
At the moment, the content of a design document is only very loosely coupled to network execution. There is no structured process how design documents get translated and implemented. It is wide open to interpretations by individual engineers who know the steps and procedures they use to make (break) or fix things in the network. As a result configuration diversity grows and tasks cannot be shared or made repeatable between team members.
“The focus should be on structuring the information and processes between your Design, Build, and Operate activities”
These processes are broken, manual and implicit. There is no structured data and users, at best, are sharing documents without a clear process. Design rules are not adhered to, different information sources exist (infamous copy/paste by engineers), knowledge is not shared, best practices not used, etc… It’s these processes that need to be aligned that is the true challenge for network automation.
The question then is how we make all these implicit logic and processes explicit while at the same time being able to deal with the unique requirements that each Service Provider has. The answer lies in how you bridge the gap between your design rules and your device configurations.
How to bridge this gap?
Welcome to our world. This is what the people behind NetYCE (short for Your Configuration Engine for the network) have been doing for the last 15 years. The key lies in segregating and abstracting the following 3 layers:
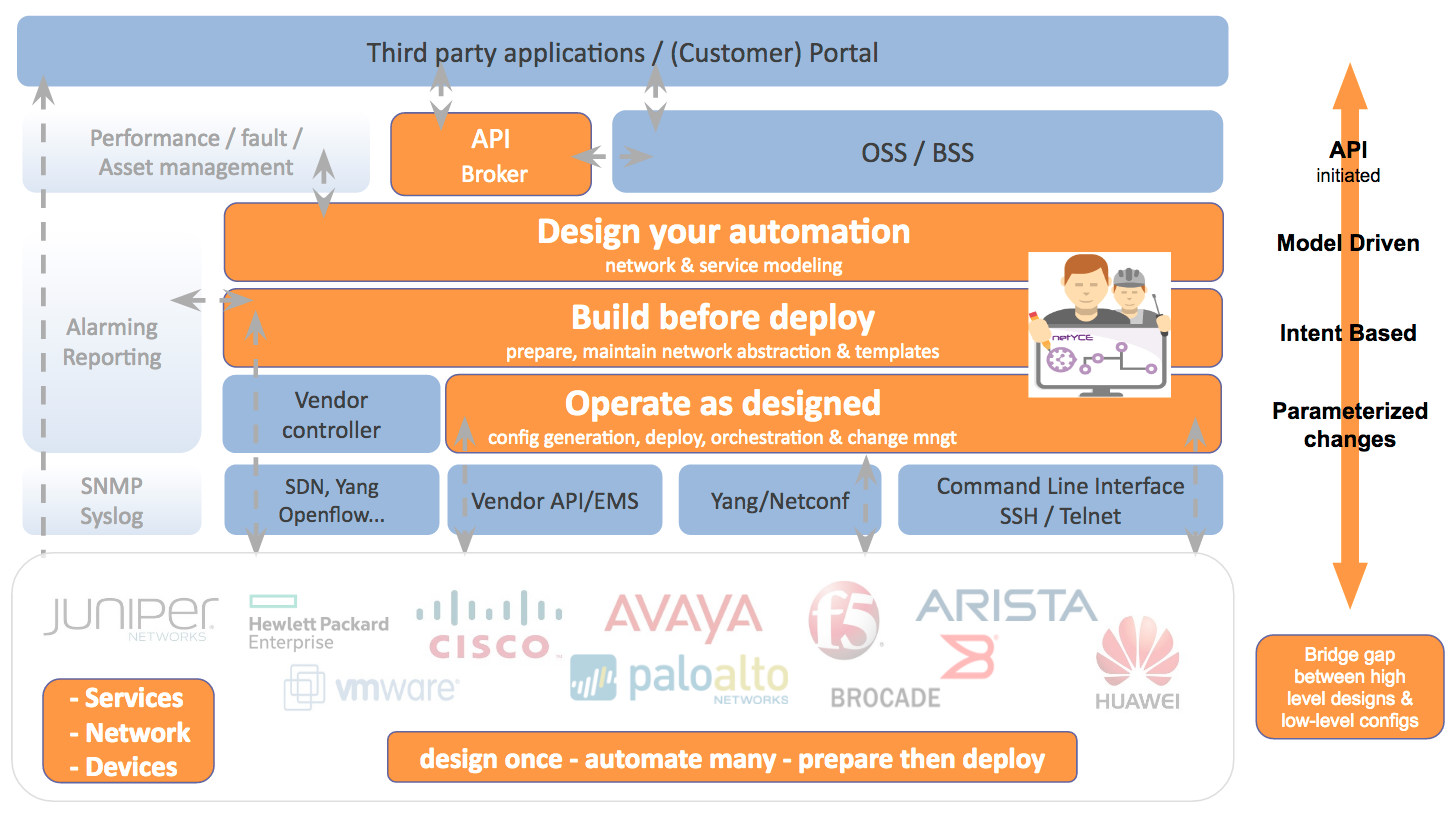
First is the Service Design layer (Design). This should allow you to model any type of network design, service, and automation rule. But also your customers, IP plans, sites and nodes, naming conventions, etc. This is where you translate your high-level design documents into executable service types that can be combined with templates. These service tasks not only manage all of the parameters, variables, and relationships required in your configurations, it also enforces anyone to apply them in a uniform way.
The templates enable you to store, structure and share any of your team’s engineering knowledge in such as way that configurations and small configlets (as designed) can be generated on the fly without any error. By anyone!
Second is the Network Abstraction layer (Build). This should allow you to store all of your network configuration information per customer, site, node (topology) and service in an abstract, vendor agnostic way. Look at this as your abstract network configuration inventory.
Not only is this important for creating flexibility and reduce vendor lock-in, but more importantly, it also offers you a way to prepare any change before you deploy them and to do this with multiple (even remote) team members. This significantly reduces the operational risks of validating status information in production.
Third is the Network Operations layer (Operate).This should enable you to have one centralized GUI plus the necessary tools to perform changes to all your individual devices in an orchestrated and controlled way. By combining this with the information from the Network Abstraction layer, all your context aware (topology- and service) information can automatically be incorporated in your low-level configs. This not only eliminates errors in the process, it also reduces the need to log into production devices.
Engineers should simply be able to schedule jobs to the network. And to guarantee that nothing can go wrong in your production network, you should be able to combine any job with your own scenarios for validation, roll backs, config diffs checks, migration steps etc.. This enforces best practices to be also used and shared among colleagues for deployments.
By combining this three-layered approach in a coherent way you not only enable automation of network changes, you also enforce standardization and compliance in your production network. And with this in place, you can now simply take things to the next level; offer self-service portals for help-desk personnel or customers, role-based access to multi-tenant networks or incorporate straight through (zero-touch) provisioning with your OSS/BSS systems.
In the next blog, we will take a deep dive into this approach and discuss the technical capabilities.